将字库数据烧录到 Flash 芯片内的方法
本文旨在提供思路和方法,同时作为一篇开发笔记分享给大家。本文中所有的软件资源、代码等可以在 Gitee 仓库: Stm32_HZK 中获取。
本文中所使用的 Flash 芯片型号为 华邦(WINBOND) 生产的 W25Q 系列的芯片,它是一款非易失性存储芯片,通信方式支持有 SPI, Dual SPI, QUAD SPI 这三种方式。 支持的最大时钟频率为 133MHz。
GBK 汉字字符集的生成
什么是 GBK 汉字字符集?
GBK 汉字字符集 是一种用于表示中文字符的字符编码。它包含了所有的中文字符,每个中文字符都有一个唯一的编码值。
通俗的来讲就是所有汉字的一个集合,这个集合按照先后顺序被排列组合起来,就形成了 GBK 汉字字符集。
GBK 字符集的编码格式
与 ASCII 码 不同的是,GBK 编码是一个 16 位的编码,每个汉字需要 2 个字节来表示。GBK 编码的双字节结构,具体分为:
- 区码 (高字节): 范围 0x81-0xFE
- 位码 (低字节): 范围 0x40-0xFE(0x7F 除外)
所以,经过计算后可以得出GBK 理论编码位置有 23940 个。计算过程如下:
- 区码(高字节)长度:
0x81-0xFE+0x01=0x7E,加上 1 则是算上起始位置。 - 位码(低字节)长度: 又称为每个区的字码数量
0x40-0xFE-0x01+0x01=0xBE,减去的 1 是被除掉的 0x7F,加上的 1 则是算上起始位置。 - 所以总的可用的编码位置一共有:
0x7E*0xBE=0x5D84个,十进制下为23940个。
举个例子说明为什么计算结果要加 1,比如有
2 3 4 5 6这几个数字,那么数字的数量就是(6-2)+1=5,小学数学问题,但是防止不懂还是提一下(doge)
为什么要生成它?
在这之前,我尝试在网络上搜索现有的 GBK 汉字字符集,但是搜索到的都是已经收录到 GBK 字符集的字库文件,而我需要的是一个完整的 GBK 字符集文件,包含所有理论上的中文字符。所以我就打算自己生成一个 GBK 汉字字符集文件。
生成 GBK 汉字字符集
本次使用 python 生成 GBK 汉字字符集。代码如下:
# 生成的索引文件会被保存到当前目录下的 GBK_INDEX.txt 中
file = open("GBK_INDEX.txt", "wb")
highByte = 0x81 # 高字节起始位置
lowByte = 0x40 # 低字节起始位置
# 文件头写入 ascii 码
# 也可以把这部分放到下一部分中,在文件尾写入 ascii 码
asciiCode = 20 # ascii 码起始字符位置
while True:
asciiCode += 1
if asciiCode > 0x7E: # 终止字符位置为 0x7E
break
file.write(bytes([asciiCode]))
while True:
# 跳过 0x7F(GBK 编码中该位码无效)
if lowByte == 0x7F:
lowByte += 1
continue
# 写入当前高低字节
file.write(bytes([highByte, lowByte]))
# 低位字节自增
lowByte += 1
# 检查低位是否溢出,即达到最大值 0xFE
if lowByte > 0xFE:
# 重置低位并增加高位
lowByte = 0x40
highByte += 1
# 检查高位是否达到终止条件
if highByte > 0xFE:
break
file.close()生成点阵字库
将我们生成好的 GBK 汉字字符集导入到 PCtoLCD2002 软件中去生成我们的点阵字库数据就可以了。图中配置的是每个中文字符的字模数据为 16x16 大小,占用 32 个字节。
- 首先打开 PCtoLCD2002 软件,对应的软件资源位于 Stm32/_HZK 仓库中
PCtoLCD2002 完美版文件夹内。 - 点击
导入大量文本按钮,选择打开文本文件 - 选择我们之前生成的 GBK_INDEX.txt 文件
- 点击
开始生成按钮,选择好保存路径后,等待软件生成完成。
计算汉字字模数据的偏移地址
在这之前,我们已经生成了连续的 23940 个 GBK 编码的中文字符,并且对每个字符都取模生成了对应的字模数据,每个中文字符的字模数据都是 32 个字节。所以在生成的字库数据中,每个汉字的字模数据都是连续存储的,我们需要根据汉字的编码值来计算出它的字模数据在 Flash 中的偏移地址。
以汉字 “啊” 为例子,它的 GBK 编码为 0xB0A1,根据 GBK 编码的规则,计算过程如下:
- 它的区码为
0xB0,由于区码的起始位置为0x81,所以区码偏移为0xB0-0x81=0x2F。 - 它的位码为
0xA1,由于位码的起始位置为0x40,并且它的值大于了0x7F,要在最终的结果上减去 1,所以位码偏移为0xA1-0x40-0x01=0x60。 - 将汉字的区码偏移和位码长度相乘,再加上位码偏移,就得到了汉字偏移量:
0x2F*0xBE+0x60=0x2342。 - 再将汉字偏移量乘以每个中文字符的字模数据大小 32 字节,就得到了汉字字模数据在 Flash 中的偏移地址:
0x2342*0x20=0x046840。
下面用一张流程图来展示计算过程(你可以自由的缩放、移动这个流程图):
flowchart TD
A[开始] --> B[输入任意汉字]
B --> C[获取该汉字的 GBK 编码<br>(双字节)]
C --> D[分离区码和位码<br>区码 = 高字节,位码 = 低字节]
D --> E[计算区码偏移<br>区码偏移 = 区码 - 0x81]
E --> F{位码 > 0x7F ?}
F -- 是 --> G[位码偏移 = 位码 - 0x40 - 0x01]
F -- 否 --> H[位码偏移 = 位码 - 0x40]
G --> I[计算汉字偏移量<br>偏移量 = 区码偏移 × 每区汉字数 + 位码偏移<br>其中每区汉字数 = 0xBE]
H --> I
I --> J[计算字模数据在 Flash 中的地址<br>地址 = 偏移量 × 每个字模大小<br>每个字模大小 = 32 字节]
J --> K[结束]
小结
若位码小于等于 0x7F,则地址计算为:
地址 = (区码 - 0x81) * 0xBE + (位码 - 0x40) * 32若位码大于 0x7F,则地址计算为:
地址 = (区码 - 0x81) * 0xBE + (位码 - 0x40 - 0x01) * 32其中,0x81 是区码的起始位置,0xBE 是每个区的字码数量,0x40 是位码的起始位置,0x01 是为了修正位码的偏移量。
验证计算结果
使用 十六进制编辑器 打开我们生成的字库文件,按下 Ctrl+G 输入 0x046840 这个位置,之后按下回车跳转到这个位置,从这个位置开始,连续读取 32 个字节,就是汉字 “啊” 的字模数据了。
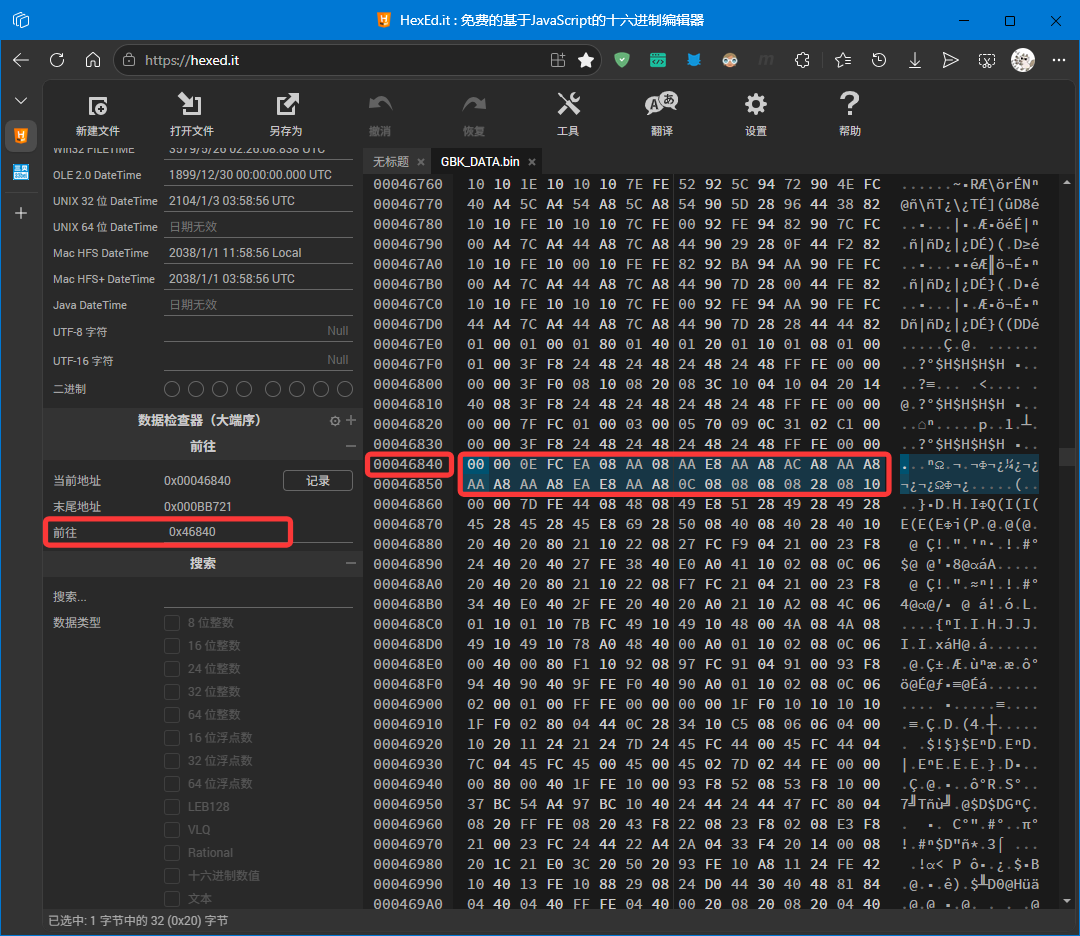
选中这些数据,把它复制下来,粘贴到 字模验证工具网站 中 (注意选择对应的取模参数,数据排列和取模方式),从图中可以看到我们的字模数据是正确的。
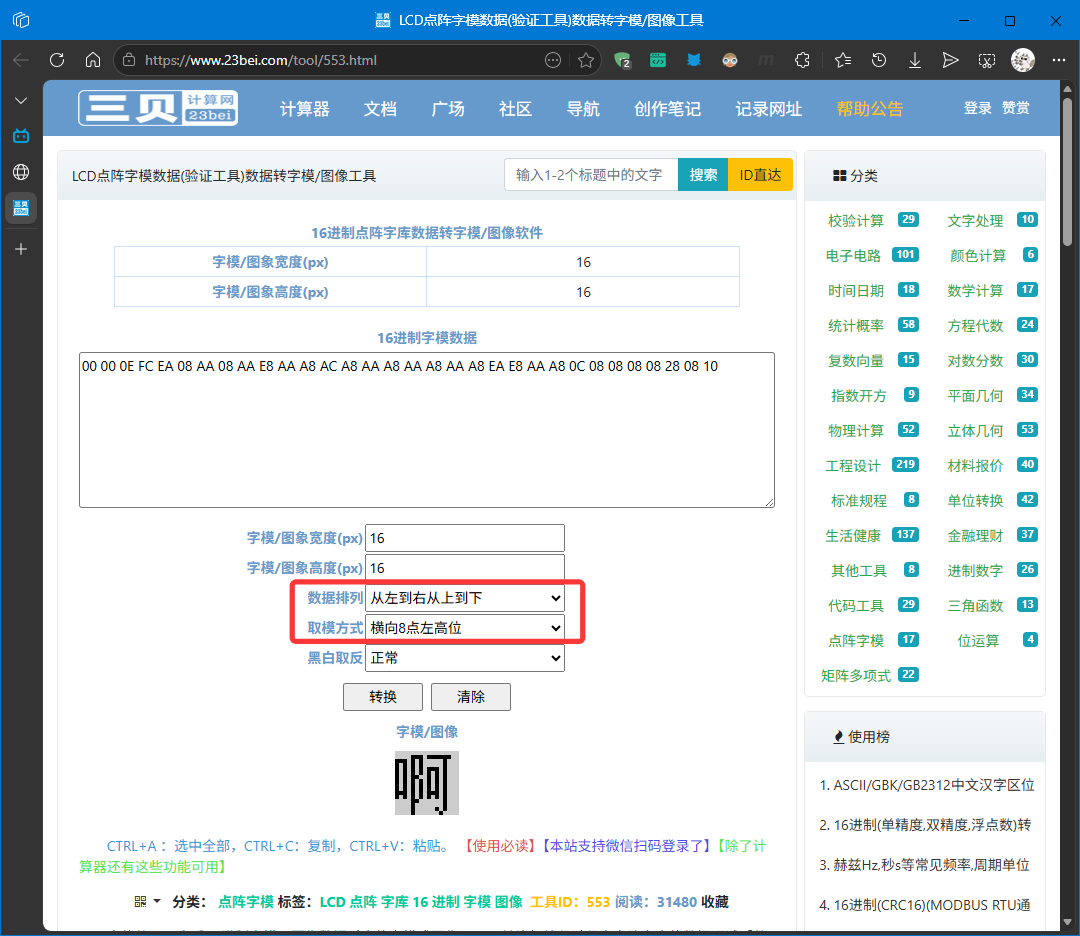
刚刚验证的是汉字 “啊” 的字模数据,它的位码大于了 0x7F,验证的是 小结 中 “若位码大于 0x7F” 这一部分的计算结果。下面以汉字 “丢” 为例子验证 “位码小于 0x7F” 这一部分的计算结果。
汉字 “丢” 的 GBK 编码为0x8147,根据 GBK 编码的规则,计算过程如下:
- 它的区码为
0x81,由于区码的起始位置为0x81,所以区码偏移为0x81-0x81=0x00。- 它的位码为
0x47,由于位码的起始位置为0x40,并且它的值小于等于 0x7F,所以位码偏移为0x47-0x40=0x07。所以它的偏移地址为
0x00*0xBE+0x07*0x20=0xE0。
跳转到0xE0这个位置就可以看到汉字 “丢” 的字模数据了。在这里不再赘述验证过程。
烧录字库数据到 Flash 芯片内
这部分内容你可以用任何方式包括但不限于 ST-LINK、J-LINK、SWD 调试器、以及最基本的串口烧录(配合 Flash 驱动程序)。在这里就不详细展开说明了。